分類モデル構築時のナレッジチャンクの影響度調整 富士通研究所:正解が少ないデータでも高精度に学習するAIの新技術「Wide Learning」を開発
- 2018/09/20
- Motor Fan illustrated編集部
富士通研究所は、学習に必要な量のデータを取得できない場合にも、高精度な判断が可能な機械学習技術「Wide Learning(ワイドラーニング)」を開発した。様々な分野においてデータを利活用するためにAIが使われてきているが、分析にかけるデータ量が少ない場合や偏りがある場合に、AIによる分析の精度に影響がおよぶ。本技術では、まず、データの項目どうしをすべて組み合わせ、その大量の組合せを仮説として、重要度の高いものを選別。さらに、仮説を構成する項目の重複関係に基づいてそれぞれの影響度を制御することで、どの仮説に対しても均等に学習することができ、データに偏りがある場合でも従来よりも高精度な判断を下すことが可能となる。また、仮説は論理的な表現で記述されているため、人間にも判断理由を理解することが可能。本技術により、判断したい対象のデータが少ない医療やマーケティングなどの現場でもAIを活用し、AIによる業務の自動化や業務支援が促進される。
近年、医療やマーケティング、金融などの様々な分野においてAIが導入されはじめ、AIの判断を活用した業務支援や自動化に対する期待が高まっている。しかし、業界や業種によっては、判断したい対象に対してAIの学習に必要な十分な量のデータを取得することが難しく、実用に耐える高い精度が出ないという問題がある。また、AIが十分に高い精度での認識・分類性能を出したとしても、なぜその答えが出てきたのか専門家や開発者自身も説明できないため、現場で説明責任を果たせずAIの導入が進まない大きな要因となっている。
従来のディープラーニングをベースとしたAIは、判断したい対象のデータ(正解データ)を十分に含む大量のデータを学習させることにより、高精度の判断を実現していた。しかし、実際の現場では判断したい対象データが極端に足りない場合が少なくない。このような場合、未知のデータに対する高精度の判断を実現することは困難だ。また、従来のディープラーニングをベースとしたAIの学習モデルは、ブラックボックス型のモデルで、AIの判断理由を説明できないという透明性の問題があった。したがって、様々な社会課題においてAIを活用していくためには、正解が少ないデータでも高精度の判断を実現し、透明性を兼ね備えた新たなAI技術の開発が求められる。
開発した技術
今回、正解データが少ない場合でも高精度に判断できる機械学習技術「Wide Learning」を新たに開発した。「Wide Learning」技術の特長は下記の2点。
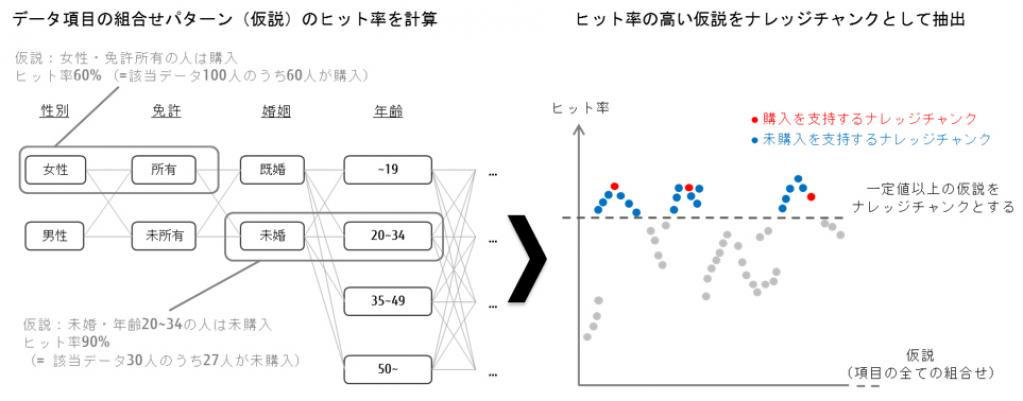
1)データ項目を組み合わせて大量の仮説を抽出
すべてのデータ項目の組合せパターンを仮説とし、各仮説に対し分類ラベルのヒット率で、その仮説の重要度を判断する。
例えば、商品購入に対しての傾向をAIで分析する際に、これまでの購入者・未購入者(分類ラベル)のデータ項目から、<女性・免許所有> <未婚・20~34歳>などすべてのパターンを組み合わせ、これらを仮説とした際に実際の商品購入者のデータとどれくらいヒットするかを分析。このとき一定以上のヒット率の仮説をナレッジチャンクとよび、重要な仮説であると定義する。これにより、元々の判断対象となるデータが十分に揃っていない場合でも、注目すべき仮説をもれなく抽出することができ、これまで考えつかなかった仮説の発見にも貢献する。
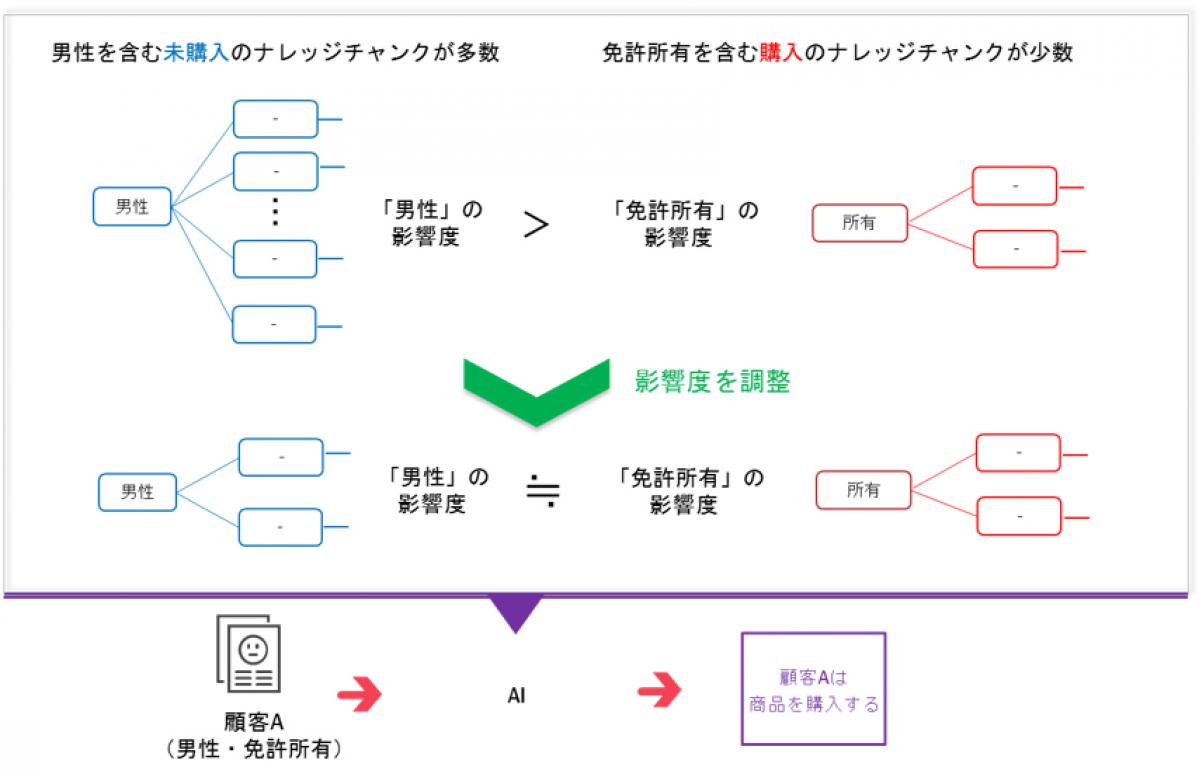
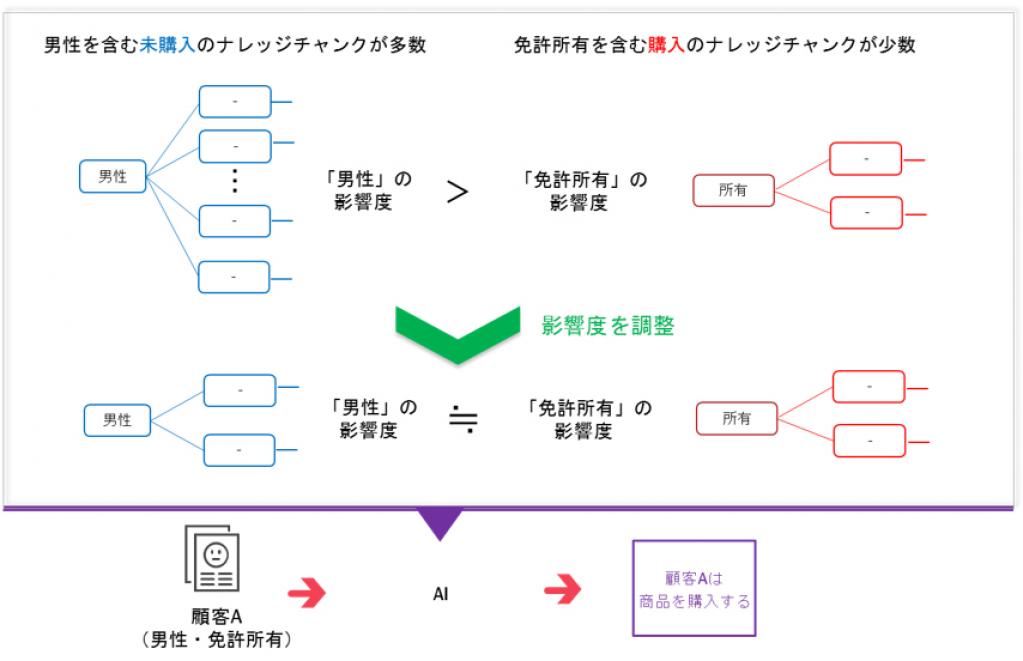
2)ナレッジチャンクの影響度を調整し高精度な分類モデルを構築
抽出した複数のナレッジチャンクとラベルに基づき分類モデルを構築する。この際に、ナレッジチャンクを構成する項目が他のナレッジチャンクを構成する項目と重複が多い場合に、分類モデルへの影響度を小さくなるように制御する。これにより、ラベルやデータに偏りがある場合にも、高精度な分類が可能なモデルを学習する。
例えば、商品購入データの中で未購入の男性のデータが大多数を占めている場合に、影響度を制御しないで学習すると、性別とは関係なく得られた<免許所有>の項目を含むナレッジチャンクが分類に影響しなくなる。開発方式では、項目の重複に応じて<男性>が含まれるナレッジチャンクの影響度を抑え、少数である<免許所有>が含まれるナレッジチャンクの影響度が相対的に大きくなるように学習することで、<男性>でも<免許所有>でも正しく分類できるモデルを構築する。
本技術の効果
本技術について、デジタルマーケティングや医療などの領域のデータに対して適用し、検証を行った。
UC Irvine Machine Learning Repositoryのマーケティングと医療領域のベンチマークデータを用いたテストで、ディープラーニングに比べ正解データを当てる精度が約10~20%向上し、サービスに加入する見込みの高い客や罹患患者を見逃す確率を約20~50%低減することを達成した。今回、約5,000件の顧客データの中で購入顧客が約230件と正解データが少ないマーケティングのデータを使ったところ、本技術を用いて販促する人を決めると、見込み顧客を販促対象から外す数をディープラーニングの分析結果である120人から74人と減らすことができた。
さらに、本技術のベースになっているナレッジチャンクが、論理的な表現形式を持つことから、判断の理由を説明できることも社会実装において有効。新たなデータに対する結果から、モデルの修正が必要だと判断した際にも、結果の理由が理解できるため、より適切な修正を施すことが可能となる。
今後、不正利用や設備故障などの低頻度の事象を扱う業務や、金融取引、医療診断などのAIの判断理由を求められる業務において実践を進め、富士通のAI技術「FUJITSU Human Centric AI Zinrai」を支える新たな機械学習技術として2019年度の実用化を目指す。
また、本技術のもつ説明可能な特性も有効に活用し、導入先の業務における判断・意思決定支援の高度化、人間との協働を含めた全体のシステムの設計などの研究開発を進めていく。
|
|
|
自動車業界の最新情報をお届けします!
Follow @MotorFanwebおすすめのバックナンバー








これが本当の実燃費だ!ステージごとにみっちり計測してみました。

日産キックス600km試乗インプレ:80km/h以上の速度域では燃費が劇...

BMW320d ディーゼルの真骨頂! 1000km一気に走破 東京〜山形往復...

日産ノート | カッコイイだけじゃない! 燃費も走りも格段に洗練...

渋滞もなんのその! スイスポの本気度はサンデードライブでこそ光...

PHEVとディーゼルで燃費はどう違う? プジョー3008HYBRID4とリフ...

スズキ・ジムニーとジムニーシエラでダート走行の燃費を計ってみた...
会員必読記事|MotorFan Tech 厳選コンテンツ

フェアレディZ432の真実 名車再考 日産フェアレディZ432 Chapter2...

マツダ ロータリーエンジン 13B-RENESISに至る技術課題と改善手法...

マツダSKYACTIV-X:常識破りのブレークスルー。ガソリンエンジン...

ターボエンジンに過給ラグが生じるわけ——普段は自然吸気状態

林義正先生、「トルクと馬力」って何が違うんですか、教えてくだ...

マツダ×トヨタのSKYACTIV-HYBRIDとはどのようなパワートレインだ...
3分でわかる! クルマとバイクのテクノロジー超簡単解説

3分でわかる! スーパーカブのエンジンが壊れない理由……のひとつ...

3分でわかる! マツダのSKYACTIV-X(スカイアクティブ-X)ってな...

スーパーカブとクロスカブの運転が楽しいのは自動遠心クラッチ付...

ホンダCB1100の並列4気筒にはなぜV8のようなドロドロ感があるのか...

ホンダ・シビック タイプRの謎、4気筒なのになぜマフラーが3本?
